
Today’s topic is not directly related to traffic monetization. But robots.txt can impact your website’s SEO and, eventually, the amount of traffic it receives. Many web admins have ruined their websites’ rankings due to botched robots.txt entries. This guide will help you avoid all of those pitfalls. Make sure to read to the end!
What is a robots.txt file?
The robots.txt, or robot exclusion protocol, is a set of web standards that controls how search engine robots crawl every web page, down to the schema markups on that page. It’s a standard text file that can even prevent web crawlers from gaining access to your whole website or parts of it.
While adjusting SEO and solving technical issues, you can start getting passive income from ads. A single line of code on your website returns regular payouts!
How does a robots.txt file look?
The syntax is simple: you give bots rules by specifying their user-agent and directives. The file has the following basic format:
Sitemap: [URL location of sitemap]
User-agent: [bot identifier]
[directive 1]
[directive 2]
[directive …]
User-agent: [another bot identifier]
[directive 1]
[directive 2]
[directive …]
How to find your robots.txt file
If your website already has a robot.txt file, you can find it by going to this URL: https://yourdomainname.com/robots.txt in your browser. For example, here’s our file
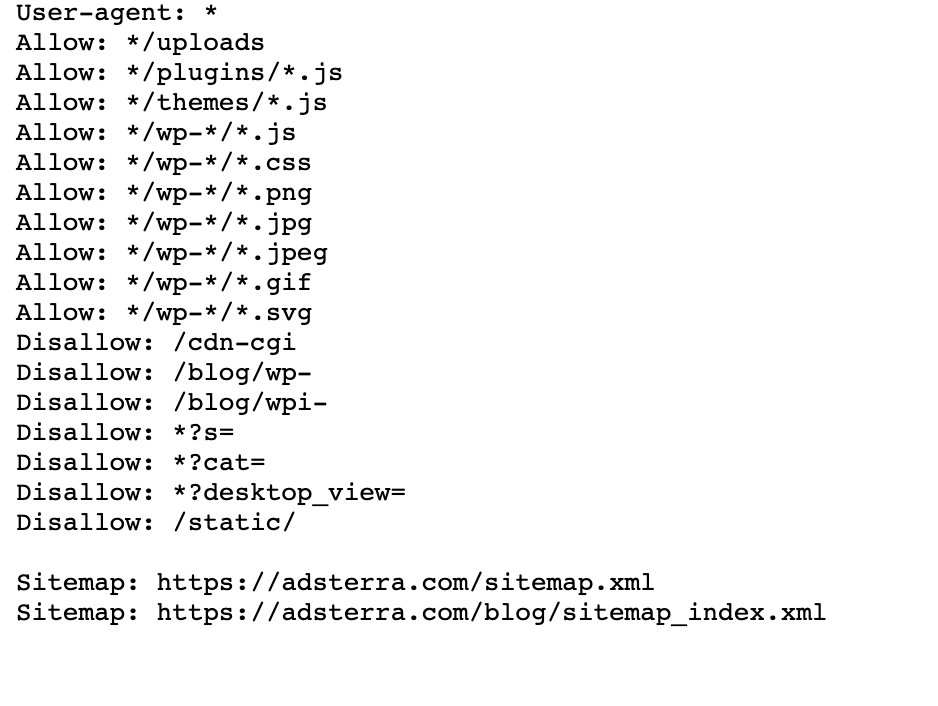
How does a Robots.txt file work?
A robots.txt file is a plain text file that does not contain any HTML markup code (hence the .txt extension). This file, like all other files on the website, is stored on the web server. Users are unlikely to visit this page because it’s not linked to any of your pages, but most web crawler bots search for it before crawling the entire website.
A robots.txt file can give bots instructions but can’t enforce those instructions. A good bot, such as a web crawler or a news feed bot, will check the file and follow the instructions before visiting any domain page. But malicious bots will either ignore or process the file to find forbidden web pages.
In a situation when a robots.txt file contains conflicting commands, the bot will use the most specific set of instructions.
Robots.txt syntax
A robots.txt file consists of several sections of ‘directives,’ each starting with a user-agent. The user-agent specifies the crawl bot with which the code communicates. You can either address all search engines at once or manage individual search engines.
Whenever a bot crawls a website, it acts on the parts of the site that are calling it.
User-agent: *
Disallow: /
User-agent: Googlebot
Disallow:
User-agent: Bingbot
Disallow: /not-for-bing/
Supported directives
Directives are guidelines that you want the user-agents you declare to follow. Google currently supports the following directives.
User-agent*
When a program connects to a web server (a robot or a regular web browser), it sends an HTTP header called “user-agent” containing basic information about its identity. Every search engine has a user-agent. Google’s robots are known as Googlebot, Yahoo’s — as Slurp, and Bing’s — as BingBot. The user-agent initiates a sequence of directives, which can apply to specific user-agents or all user-agents.
Allow
The allow directive tells search engines to crawl a page or subdirectory, even a restricted directory. For example, if you want search engines to be unable to access all of your blog’s posts except one, your robots.txt file might look like this:
User-agent: *
Disallow: /blog
Allow: /blog/allowed-post
However, search engines can access /blog/allowed-post but they are unable to gain access to:
/blog/another-post
/blog/yet-another-post
/blog/download-me.pd
Disallow
The disallow directive (which is added to a website’s robots.txt file) tells search engines not to crawl a specific page. In most cases, this will also prevent a page from appearing in search results.
You can use this directive to instruct search engines not to crawl files and pages in a specific folder you’re hiding from the general public. For example, content that you are still working on but mistakenly published. Your robots.txt file might look like this if you want to prevent all search engines from accessing your blog:
User-agent: *
Disallow: /blog
This means all the subdirectories of the /blog directory would also not be crawled. This would also block Google from accessing URLs containing /blog.
Sitemap
Sitemaps are a list of pages you want search engines to crawl and index. If you use the sitemap directive, search engines will know the location of your XML sitemap. The best option is to submit them to the search engines’ webmaster tools because each can provide valuable information about your website for visitors.
It’s important to note that repeating the sitemap directive for each user-agent is unnecessary, and it doesn’t apply to one search-agent. Add your sitemap directives at the beginning or end of your robots.txt file.
An example of a sitemap directive in the file:
Sitemap: https://www.domain.com/sitemap.xml
User-agent: Googlebot
Disallow: /blog/
Allow: /blog/post-title/
User-agent: Bingbot
Disallow: /services/
Unsupported directives
The following are directives that Google no longer supports — some of which were technically never endorsed.
Crawl-delay
Yahoo, Bing, and Yandex rapidly respond to websites’ indexing and react to the crawl-delay directive, which keeps them in check for a while.
Apply this line to your block:
User-agent: Bingbot
Crawl-delay: 10
It means that the search engines can wait for ten seconds before crawling the website or ten seconds before re-accessing the website after crawling, which is the same thing but slightly different depending on the user-agent in use.
Noindex
The noindex meta tag is a great way to prevent search engines from indexing one of your pages. The tag allows bots to access the web pages, but it also informs robots not to index them.
- HTTP Response header with noindex tag. You can implement this tag in two ways: an HTTP response header with an X-Robots-Tag or a <meta> tag placed within the <head> section. This is how your <meta> tag should look:
<meta name=”robots” content=”noindex”>
- 404 & 410 HTTP status code. The 404 and 410 status codes indicate that a page is no longer available. After crawling and processing 404/410 pages, they automatically remove them from Google’s index. To reduce the risk of 404 and 410 error pages, crawl your website regularly and use 301 redirects to direct traffic to an existing page where necessary.
Nofollow
Nofollow directs search engines not to follow links on pages and files under a specific path. Since March 1, 2020, Google no longer considers nofollow attributes as directives. Instead, they will be hints, much like canonical tags. If you want a “nofollow” attribute for all links on a page, use the robot’s meta tag, the x-robots header, or the rel= “nofollow” link attribute.
Previously you could use the following directive to prevent Google from following all links on your blog:
User-agent: Googlebot
Nofollow: /blog/
Do you need a robots.txt file?
Many less complex websites do not need one. While Google doesn’t usually index web pages blocked by robots.txt, there’s no way of guaranteeing that these pages don’t appear on search results. Having this file gives you more control and security of content on your website over search engines.
Robots files also help you accomplish the following:
- Prevent duplicate content from being crawled.
- Maintain privacy for different website sections.
- Restrict internal search results crawling.
- Prevent server overload.
- Prevent “crawl budget” waste.
- Keep images, videos, and resource files out of Google search results.
These measures ultimately affect your SEO tactics. For example, duplicate content confuses search engines and forces them to choose which of two pages to rank first. Regardless of who created the content, Google may not select the original page for the top search results.
In cases where Google detects duplicate content intended to deceive users or manipulate rankings, they’ll adjust the indexing and ranking of your website. As a result, your site’s ranking may suffer or be removed entirely from Google’s index, disappearing from search results.
Maintaining privacy for different website sections also improves your website security and protects it from hackers. In the long run, these measures will make your website more secure, trustworthy, and profitable.
Are you a website owner who wants to profit from traffic? With Adsterra, you will get passive income from any website!
Creating a robots.txt file
You’ll need a text editor such as Notepad.
- Create a new sheet, save the blank page as ‘robots.txt,’ and start typing directives in the blank .txt document.
- Login to your cPanel, navigate to the site’s root directory, look for the public_html folder.
- Drag your file into this folder and then double-check if the file’s permission is correctly set.
You can write, read, and edit the file as the owner, but third parties are not permitted. A “0644” permission code should appear in the file. If not, right-click the file and choose “file permission.”
Robots.txt file: SEO best practices
Use a new line for each directive
You need to declare each directive on a separate line. Otherwise, search engines will be confused.
User-agent: *
Disallow: /directory/
Disallow: /another-directory/
Use wildcards to simplify instructions
You can use wildcards (*) for all user-agents and match URL patterns when declaring directives. Wildcard works well for URLs that have a uniform pattern. For example, you might want to prevent all filter pages with a question mark (?) in their URLs from being crawled.
User-agent: *
Disallow: /*?
Use the dollar sign “$” to specify the end of a URL
Search engines cannot access URLs that end in extensions like .pdf. That means they won’t be able to access /file.pdf, but they will be able to access /file.pdf?id=68937586, which doesn’t end in “.pdf.” For example, if you want to prevent search engines from accessing all PDF files on your website, your robots.txt file might look like this:
User-agent: *
Disallow: /*.pdf$
Use each user-agent only once
In Google, it doesn’t matter if you use the same user-agent more than once. It will simply compile all of the rules from the various declarations into a single directive and follow it. However, declaring each user-agent only once makes sense because it is less confusing.
Keeping your directives tidy and simple reduces the risk of critical errors. For example, if your robots.txt file contained the following user-agents and directives.
User-agent: Googlebot
Disallow: /a/
User-agent: Googlebot
Disallow: /b/
Use specific instructions to avoid unintentional errors
When setting directives, failing to provide specific instructions can create errors that can harm your SEO. Assume you have a multilingual site and are working on a German version for the /de/ subdirectory.
You don’t want search engines to be able to access it because it isn’t ready yet. The following robots.txt file will prevent search engines from indexing that subfolder and its contents:
User-agent: *
Disallow: /de
However, it will restrict search engines from crawling any pages or files that begin with the /de. In this case, adding a trailing slash is the simple solution.
User-agent: *
Disallow: /de/
Enter comments in robots.txt file with a hash
Comments help developers and possibly even you to understand your robots.txt file. Start the line with a hash (#) to include a comment. Crawlers ignore lines beginning with a hash.
# This instructs the Bing bot to not crawl our site.
User-agent: Bingbot
Disallow: /
Use different robots.txt files for each subdomain
Robots.txt only affects crawling on its host domain. You’ll need another file to restrict crawling on a different subdomain. For example, if you host your main website on example.com and your blog on blog.example.com, you’ll need two robots.txt files. Place one in the main domain’s root directory, while the other file should be in the blog’s root directory.
Do not block good content
Don’t use a robots.txt file or a noindex tag to block any quality content that you want to make public to avoid negative effects on SEO results. Thoroughly check noindex tags and disallow rules on your pages.
Don’t overuse crawl delay
We’ve explained the crawl delay, but you should not use it frequently because it limits bots from crawling all the pages. It may work for some websites, but you may be hurting your rankings and traffic if you have a large website.
Pay attention to case sensitivity
Robots.txt file is case-sensitive, so you need to ensure that you create a robots file in the correct format. The robots file should be named ‘robots.txt’ with all lowercase letters. Else, it won’t work.
Other best practices:
- Ensure that you don’t block your website’s content or sections from crawling.
- Don’t use robots.txt to keep sensitive data (private user information) out of SERP results. Use a different method, such as data encryption or the noindex meta directive, to restrict access if other pages link directly to the private page.
- Some search engines have more than one user-agent. Google, for example, uses Googlebot for organic searches and Googlebot-Image for images. Specifying directives for each search engine’s multiple crawlers isn’t necessary because most user agents from the same search engine follow the same rules.
- A search engine caches the robots.txt contents but updates them daily. If you change the file and want to update it faster, you can submit the file URL to Google.
Using robots.txt to prevent content indexing
Disabling a page is the most effective way to prevent bots from crawling it directly. However, it’ll not work in the following situations:
- If another source has links to the page, the bots will still crawl and index it.
- Illegitimate bots will continue to crawl and index the content.
Using robots.txt to shield private content
Some private content, such as PDFs or thank you pages, can still be indexable even if you block the bots. Placing all of your exclusive pages behind a login is one of the best ways to strengthen the disallow directive. Your content will remain available, but your visitors will take an extra step in accessing it.
Using robots.txt to hide malicious duplicate content
Duplicate content is either identical or very similar to other content in the same language. Google tries to index and show pages with unique content. For example, if your site has “regular” and “printer” versions of each article and a noindex tag blocks neither, they’ll list one of them.
Example robots.txt files
The following are a few sample robots.txt files. These are primarily for ideas, but if one of them meets your needs, copy and paste it into a text document, save it as “robots.txt,” and upload it to the proper directory.
All-access for all bots
There are several ways to tell search engines to access all files, including having an empty robots.txt file or none.
User-agent: *
Disallow:
No access for all bots
The following robots.txt file instructs all search engines to avoid accessing the entire site:
User-agent: *
Disallow: /
Block one subdirectory for all bots
User-agent: *
Disallow: /folder/
Block one subdirectory for all bots (with one file within allowed)
User-agent: *
Disallow: /folder/
Allow: /folder/page.html
Block one file for all bots
User-agent: *
Disallow: /this-is-a-file.pdf
Block one filetype (PDF) for all bots
User-agent: *
Disallow: /*.pdf$
Block all parameterized URLs for Googlebot only
User-agent: Googlebot
Disallow: /*?
How to test your robots.txt file for errors
Mistakes in Robots.txt can be severe, so it’s important to monitor them. Check the “Coverage” report in Search Console regularly for issues related to robot.txt. Some of the errors you might encounter, what they mean, and how to fix them are listed below.
Submitted URL blocked by robots.txt
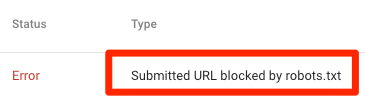
It indicates that robots.txt has blocked at least one of the URLs in your sitemap(s). If your sitemap is correct and doesn’t include canonicalized, noindexed, or redirected pages, then robots.txt should not block any pages you send. If they are, identify the affected pages and remove the block from your robots.txt file.
You can use Google’s robots.txt tester to identify the blocking directive. Be careful when editing your robots.txt file because a mistake can affect other pages or files.
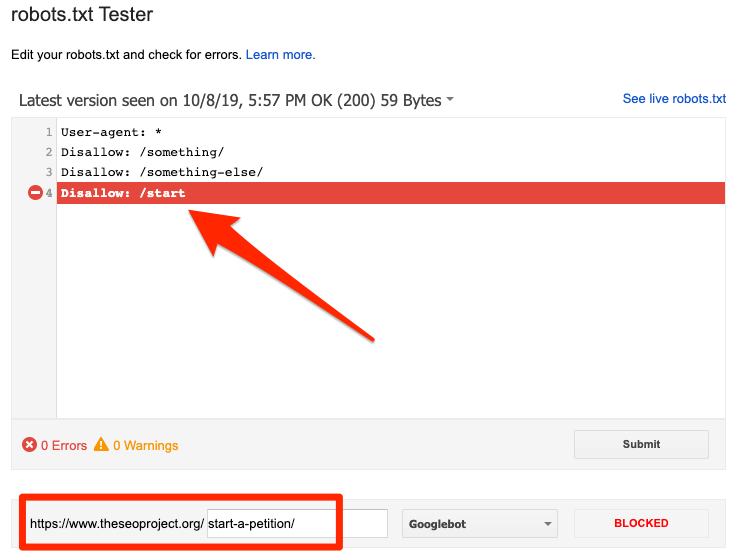
Blocked by robots.txt
This error indicates that robots.txt has blocked content that Google can’t index. Remove the crawl block in robots.txt if this content is crucial and should be indexed. (Also, check that the content isn’t noindexed.)
If you want to exclude content from Google’s index, use a robot’s meta tag or x-robots-header and remove the crawl block. That’s the only way to keep content out of Google’s index.
Indexed, though blocked by robots.txt
It means that Google still indexes some of the content blocked by robots.txt. Robots.txt is not the solution to prevent your content from displaying in Google search results.
To prevent indexing, remove the crawl block and replace it with a meta robots tag or x-robots-tag HTTP header. If you accidentally blocked this content and want Google to index it, remove the crawl block in robots.txt. It can assist in improving the content’s visibility in Google searches.
Robots.txt vs meta robots vs x-robots
What differentiates these three robot commands? Robots.txt is a simple text file, while meta and x-robots are meta directives. Beyond their fundamental roles, the three have distinct functions. Robots.txt specifies the crawling behavior for the entire website or directory, whereas meta and x-robots define indexation behavior for individual pages (or page elements).
Further reading
Useful resources
- Wikipedia: Robots Exclusion Protocol
- Google’s documentation on Robots.txt
- Bing (and Yahoo) Documentation on Robots.txt
- Directives explained
- Yandex documentation on Robots.txt
Wrapping up
We hope you’ve fully grasped the importance of robot.txt file and its contributions to your overall SEO practice and website profitability. If you’re still struggling with getting income from your website, you won’t need coding to start earning with Adsterra ads. Put an ad code on your HTML, WordPress, or Blogger website and start turning a profit today!